The skip list is an alternative to balanced search trees, especially suited for distributed applications. MemSQL is the main adopter, using skip lists as its primary index structure, but they’re also used in Redis to implement ordered sets.
This image from the paper shows what the data structure looks like. A node contains k pointers, with the ith pointer pointing to the next node of level i:
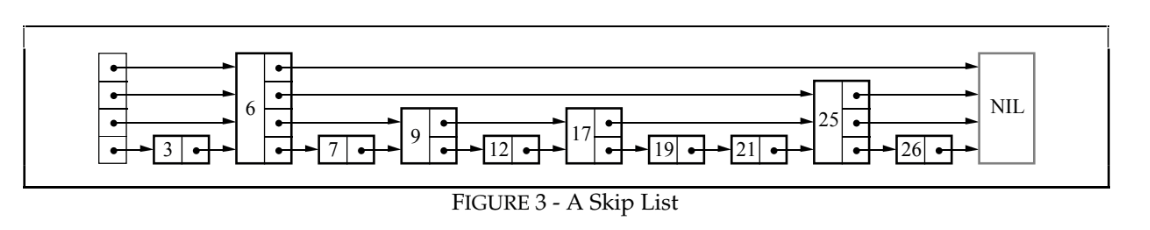 When a node is inserted, it is given a random level to represent it: level 1 with 50% probability, 2 with 25%, etc. Searches are started at the top level, with each node acting as an index to the lower level. This process is like a binary search – if the skip list is balanced, the search traverses only 1-2 nodes at each level.
When a node is inserted, it is given a random level to represent it: level 1 with 50% probability, 2 with 25%, etc. Searches are started at the top level, with each node acting as an index to the lower level. This process is like a binary search – if the skip list is balanced, the search traverses only 1-2 nodes at each level.
The paper defends the claims that 1) concurrency guarantees are easier to implement for skip lists than for balanced trees, requiring only write locks on the nodes being written, and 2) the data structure is very unlikely to become significantly unbalanced. With skip lists having the advantage of 1) and having similar performance to balanced trees, they appear to provide an advantage in concurrent applications.
To ensure that readers are not disrupted by writes in the absence of read locks, x is updated to point to its predecessor after removing x. Proofs are supplied for the correctness guarantees, among them that the list remains sorted and the lock is held only by the deleted key.
Although the worst case search time is O(n), in the case, for example, that the only node at each level i is the first node in the list at level 0, this is an unlikely outcome. The probability distribution over the comparisons required is similar to that of the number of coin flips needed to see k heads, where k is equal to the number of levels. Showing that distribution is apparently left by the authors as an exercise for the reader, but it makes intuitive sense: the most likely outcome is 1-2 comparisons on each level, corresponding to the most likely outcomes of 1 or 2 coin flips needed to see 1 head.